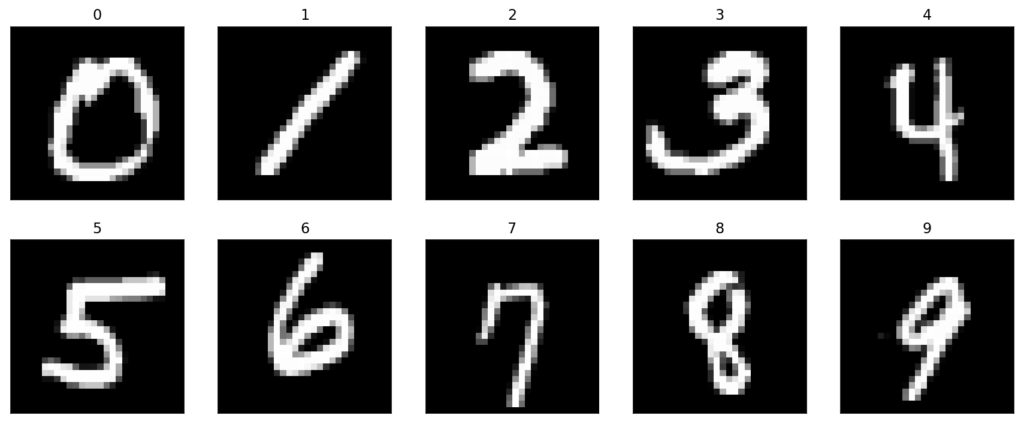Este artículo fue escrito originalmente en Inglés. Sin embargo, una versión traducida automáticamente se encuentra aquí.
The complete scientific paper with a detailed description of all the performed experiments and their solutions is available aquí.
In September of this year, I moved to Prague (Czech Republic 🇨🇿) to spend five months studying at the Czech Technical University in Prague (ČVUT) as part of an international exchange program during the last semester of my Bachelor’s degree.
For the semestral work of one of the courses that I am taking, I have had the opportunity of doing some research to compare several Artificial Intelligence approaches for the same purpose: recognizing and classifying handwritten digits.
The task of recognizing handwritten digits consists of observing an image of a written number and determining to which digit the image corresponds. This task, which is trivial for humans, has been deeply studied in the AI field, obtaining almost perfect results. However, the objective of this research was not (only) to find the most accurate approach to take: it was to find a balance between high accuracy and high ‘efficiency’ (i.e., a model that required the least amount of computing resources).
The dataset
MNIST, a very well-known dataset of computer vision, was the employed dataset for all the experiments that were carried out. This dataset has served since its release as the basis for benchmarking classification algorithms. It consists of a training set of 60K examples and a test set of 10K examples.
Sample digits from the MNIST dataset
Although this dataset is effectively solved, it is still widely used for estimating the performance of some models, and deciding how to explore possible improvements. There also exist several variants of this dataset with different types of data, designed for similar purposes.
Experiments
During the whole research, a total of four computational intelligence techniques were used, with at least three variations for each of them in order to optimize as far as possible the accuracy of each model. A brief description of each of them follows.
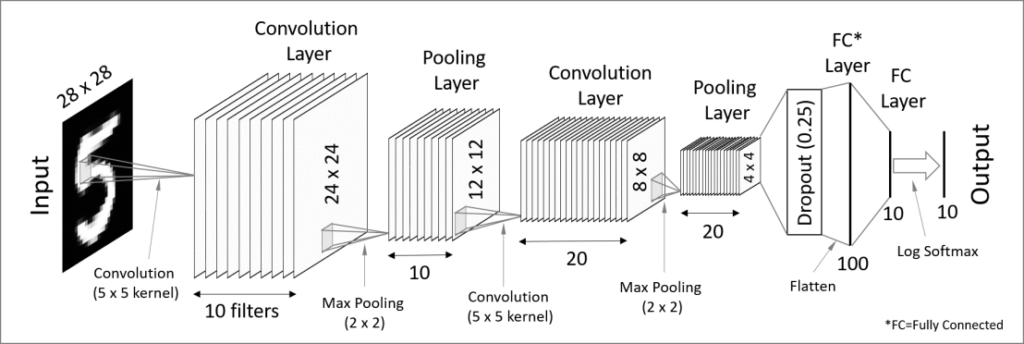
Convolutional Neural Networks
CNNs are Deep Learning models that assign importance to various aspects of the input samples and are able to differentiate them from each other. The preprocessing required using this approach is much lower when compared to other classification algorithms, and the architecture is analogous to that of the connectivity pattern of neurons in the human brain.
Example scheme of a CNN designed for the MNIST dataset
After designing a model and applying certain modifications to try to improve the final results, an accuracy of 98.85% was reached during training; and 99.31% during testing.
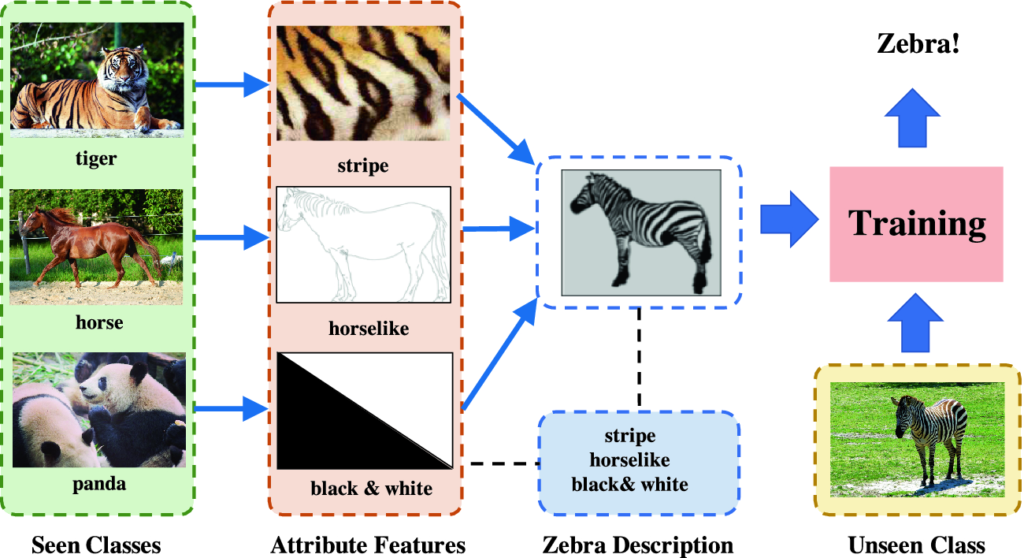
Zero-shot learning
ZSL is a problem setup in machine learning where, at test time, a learner observes samples from classes that were not observed during training, and needs to predict the class they belong to. These methods generally work by associating observed and non-observed classes through some form of auxiliary information, which encodes distinguishing properties of objects.
Example scheme of a ZSL model
A model was designed in which some digits where provided in the training phase, and some only in the testing (inference) phase, an accuracy of 72.42% was reached during training; and 48.06% during testing.
However, it must be taken into account that this is a predictive approach with a limited amount of information in training time, an aspect that makes the results still considerably good.
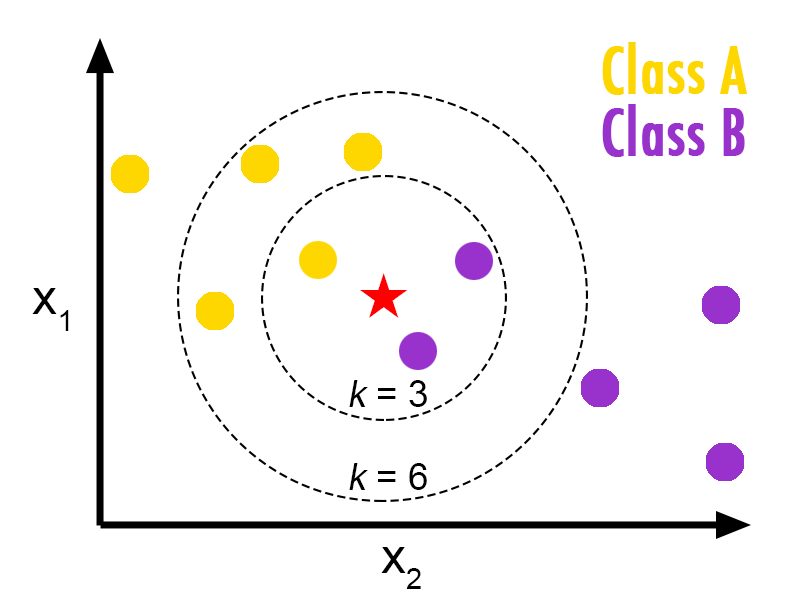
k-Nearest Neighbors classifier
k-NN is a non-parametric classification method used for classification, among others. The input consists of the k closest training examples in a dataset, and the output is a class membership. An object is classified to the most common class among its nearest neighbors.
k-NN method classification example
In this case, data was preprocessed using the PCA dimensionality reduction technique (to remove noisy data in each sample), and then classified using the k-NN method, using different values for k. An accuracy of 97.60% was reached during training; and 97.16% during testing.
Probability distributions
Finally, the last tested approach was to assume that the data followed different probability distributions, and to try estimating its parameters. In total, three distributions were explored.
Some smoothing techniques were applied on the data to avoid overfitting and, because each of these probability distributions are suitable for different kinds of data, it was required to preprocess the samples in some cases.
The results obtained for each of the distributions were:
Bernoulli distribution: 83.47% training | 84.38% testing
Multinomial distribution: 82.15% training | 83.67% testing
Gaussian distribution: 95.73% training | 95.82% testing
Conclusions
After running all the experiments, several interesting results were obtained. As in can be seen, the digit recognition task still has many aspects to be explored in order to find the most optimal approach to take, finding a balance between accuracy and efficiency in terms of computing requirements.
The numbers show that the CNN model is the best performing one, followed closely by the k-NN approach. Considering the difficulty of training both approaches, and due to a very small difference in both results, the most efficient choice in this case would be to go for the second one.
Moreover, with respect to the probability distributions, several promising results were obtained for the Gaussian case, with an accuracy close to that of the previous two best approaches. However, the samples do not fit as well into the Bernoulli and Multinomial distributions.
Finally, the ZSL learning method obtained the worst results. Nevertheless, that model is, in fact, characterized for having the least amount of information input of all the considered approaches. It can be concluded that altough in MNIST the amount of classes is very well-defined, the results would be remarkable for an expandable class dataset with more dynamic information.
Este artículo fue escrito originalmente en Español y refleja la experiencia vivida por un ciudadano en España. Sin embargo, una versión del artículo traducida automáticamente se encuentra aquí.
Una versión de este artículo en formato PDF lista para imprimir también está disponible aquí.
Ha llegado el final de un año eterno para muchos, y que ha traído malas noticias para todos. Sin embargo, haciendo balance de lo ocurrido en estos últimos 12 meses, siempre hay experiencias de las que aprender y aspectos positivos que recordar.
Es por ello que he decidido escribir esta entrada, alejada de la temática general de mis publicaciones. En ella intento hacer una revisión general del año aplicable a todos, pero que también utilizaré a modo de recuerdo personal con experiencias que diferencio en cursiva.
Antes de comenzar, quisiera dedicar un párrafo a todas las personas que han perdido la vida o se han visto severamente afectadas por esta pandemia, inesperada y muy desafortunada. El aspecto sanitario es una muy mala noticia y queda totalmente fuera del ámbito al que se refiere esta entrada.
Comienzo del año
Aunque para muchos ha quedado en el olvido, en la mayor parte del mundo 2020 no ha sido solo pandemia. Durante el primer cuarto de año, nuestras vidas fueron una continuación del año anterior, el estilo de vida cotidiano y también con la amenaza cada vez más fuerte de la existencia de un cierto virus que se expandía por todas partes.
En mi caso, durante esta época del año pude clasificarme junto a mi equipo a las finales de la liga universitaria de eSports, en la que obtuvimos muy buenos resultados quedando primeros de grupo. Si los resultados eran buenos en la siguiente fase, tendríamos la oportunidad de viajar a Madrid para disputar una final presencial.
Finales del torneo universitario de años anteriores (fuente: University Esports)
Por otro lado, también tuve la oportunidad de participar en mi primer concurso de programación competitiva por equipos (la fase local del concurso Ada Byron) y quedar en el primer puesto junto a dos compañeros de clase. Una experiencia gratificante después de varios meses de entrenamiento que nos clasificaba para la fase nacional que se realizaba de forma presencial.
Fase local del concurso de programación competitiva Ada Byron (fuente: ETSINF UPV)
Meses de confinamiento
Llegó el día en el que aquella enfermedad que se propagaba a gran velocidad por el mundo ya era considerada una pandemia mundial y se decretó el Estado de Alarma y confinamiento total en España. Esto ocurrió de forma similar y prácticamente simultánea en muchos otros lugares y supuso una parada en seco de las vidas de miles de personas, que veían canceladas todas sus tareas y proyectos pendientes con mucha incertidumbre sobre el futuro.
Por mi parte, tanto el torneo universitario, que prometía una final presencial; como el concurso de programación, que necesitaba de un espacio cerrado para disputar su final, quedaron cancelados junto a otros viajes que tenía planeados.
Junto a ello, la actividad universitaria, que no estaba en su mayoría preparada para una situación así, quedó también parada sin ninguna información por el momento.
Tener de un momento a otro las 24 horas del día a disposición para hacer lo que cada uno quisiera fue desesperante para muchos, debido a una preocupación lógica por su futuro académico o profesional; o simplemente por no saber cómo rellenar con actividades tanto tiempo que antes estaba ocupado.
Sin embargo, este momento fue una oportunidad que permitió escapar durante un tiempo de una ajetreada y estresante rutina para dedicarlo a uno mismo y también para invertirlo en proyectos personales que quizás todos habíamos dejado aparcados por las obligaciones cotidianas. Fue un respiro inesperado.
También permitió a organizaciones y empresas de todo tipo experimentar con nuevas metodologías de funcionamiento a distancia con las que no se habrían atrevido a jugar en otras circunstancias, simplemente por el desconocimiento de su eficacia.
Finalmente, la competición de programación resultó quedar cancelada, pero el torneo universitario se jugó online, quedando finalistas a nivel nacional con un resultado muy bueno.
En último lugar, nos ayudó a valorar las relaciones interpersonales y también a buscar nuevas formas de comunicarnos con la gente a la que queríamos.
Nueva normalidad
Pasados unos 3 meses de confinamiento, la expansión del virus comenzó a relajarse, y con ello las medidas restrictivas, que permitieron volver a una cierta normalidad. Dicha normalidad cambiaba la forma en la que la gente se reunía en espacios públicos, y ahora las multitudes era algo completamente impensable.
Este hecho eliminó fiestas, grandes celebraciones, festivales, y en general todo evento que reuniese en un mismo espacio a grandes cantidades de personas. Además, imponía el uso de mascarilla como medida de protección.
Con estas medidas, y también en parte durante el confinamiento anterior, se tuvieron que buscar nuevas formas de entretenimiento que en muchos casos no eran las habituales, lo que permitió descubrir hobbies, descubrir actividades nuevas, incluso visitar nuevos lugares.
Respecto a mi experiencia, noté el cambio en las actividades que realizaba al aire libre ya que probé muchas actividades que previamente no habría planeado. El entretenimiento en casa no varió mucho respecto a la ‘antigua normalidad’.
A la llegada de septiembre, la ya extendida tendencia del teletrabajo también me permitió compaginar mi horario lectivo de clases con una primera toma de contacto con el mundo laboral, en el que actualmente sigo adentrándome.
Fin del año (resumen)
Haciendo balance de este año, considerados todos los aspectos anteriores, debo decir que puedo equilibrar la balanza en aspectos positivos y negativos.
Es cierto que 2020 me ha quitado varios eventos que tenía planeados y de los que tenía ganas, pero por otro lado también es verdad que me ha dado muchas otras experiencias y algunas de ellas no habrían sido posibles sin la situación que hemos vivido.
Este inicio de década nos ha dado una nueva perspectiva sobre la forma en que nos relacionamos con la gente y también ha permitido a mucha gente conocerse a sí misma, dando un parón a la rutina agitada que muchos llevábamos, y permitiendo dedicar más tiempo a uno mismo.
También ha permitido experimentar con nuevas metodologías y en general nuevas experiencias a todos, que en situaciones normales muchos nunca se habrían arriesgado a probar.
Aún así, una pandemia mundial no es una buena noticia para nadie pero, por suerte y coincidiendo con el final del año, podemos ver la luz al final del túnel.
Feliz año nuevo 2021, para el que sólo deseo que no haga falta una reflexión como esta para obtener aspectos positivos, sino que sean más que evidentes.
Este artículo fue escrito originalmente en Inglés. Sin embargo, una versión traducida automáticamente se encuentra aquí.
When it comes to hosting public services online (such as a website, the backend of an application…), several options can be considered. The most common one is to rent a dedicated server from a hosting company and to host the desired service there. However, this option can end up being too costly depending on the hardware and software needs of such service, that could lead us to consider an alternative option.
A great choice could be to host our own server, either at home or in the office. In that case, two problems arise: having a dynamic IP, which is what most ISPs offer to the general public (and could be solved by using Dynamic DNS); and the hassle of sharing the public IP of our office/home, so that anyone can connect to the service (and also attack it).
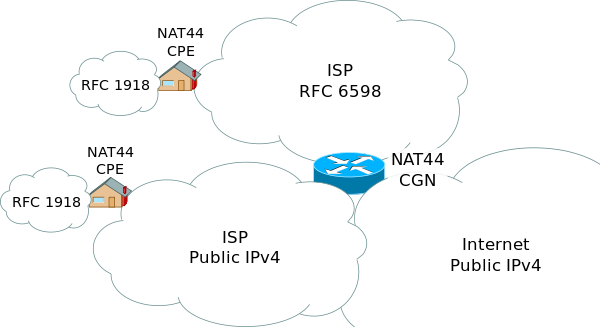
Moreover, due to the IPv4 address exhaustion problem[1], lately several ISPs are starting to implement a network design approach known as Carrier-Grade NAT[2] (or CG-NAT), that groups several clients in the same public IP, which does not allow for port forwarding, and could make it impossible to host any public service from our local network.
Figure 1. CG-NAT scheme
In those cases, or in any other in which it is of our interest to hide the IP of a computer that hosts a public service, a reverse proxy could be the solution to that problem.
Definition
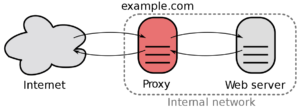
A reverse proxy[3] can be defined as a type of proxy server that retrieves resources on behalf of a client from one or more servers. These resources are then returned to the client, appearing as if they originated from the server itself.
Figure 2. Reverse proxy diagram
The process of interchanging network packets would be as follows:
The client connects to the proxy‘s IP, sending some packets
The proxy redirects those packets to the final server through a VPN.
The final server processes the request and returns the packets to the proxy.
The proxy sends the reply to the client, who sees from his perspective that the packets have been processed in the proxy.
Using this method, the IP that would be exposed to the Internet would be the proxy one, so in case of receiving an attack, it would be enough to shutdown the proxy machine in order to stop the attack and to save the local network from going down.
Installation
For the installation process[4], it is assumed that both systems run a Debian-based Linux distribution. The following steps are divided into two parts: the proxy server and the final server side.
1: Proxy server
For the proxy server, iptables will be the software in charge of routing the packets to the final server. Although it comes preinstalled in most Linux distributions, we will make sure by running:
sudo apt-get install iptables
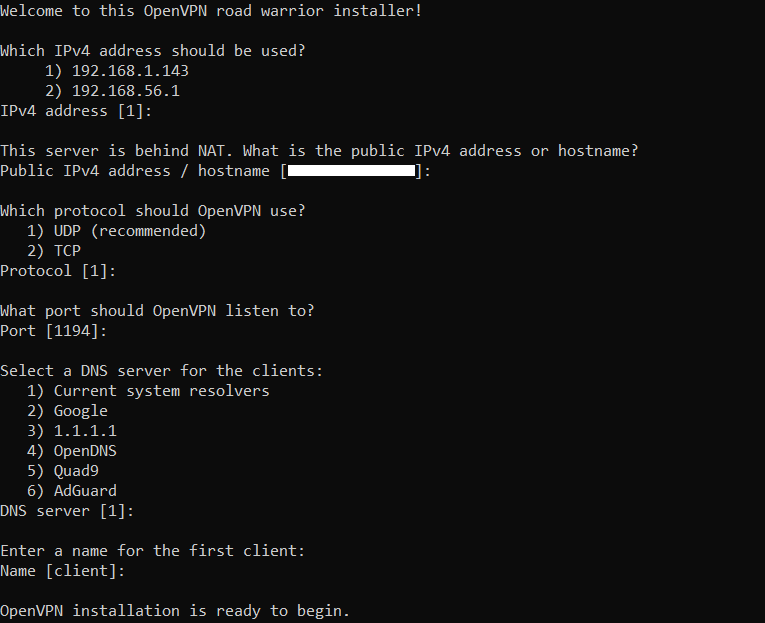
Once the installation ends, the next step is to install the VPN server that will establish the connection between the proxy and the final server, which in this case is OpenVPN. To do so, we will run the following command[5]:
The installer will ask for several preferences, that you can mostly leave with their default values. When the server finishes its installation, it will be automatically started, and a VPN profile with the ‘.ovpn‘ extension will be created. That file needs to be transferred to the final server.
2: Final server
Now that we already have the VPN up and running, we can connect to it from our final server. To do so, first of all the OpenVPN client must be installed, by running:
sudo apt-get install openvpn
When the installation finishes, we can now connect to the server. We will navigate to the folder in which the previous ‘.ovpn‘ file is now located, and then the connection can be started by running:
sudo openvpn profile.ovpn
At this time the tunnel between the proxy and the final server is already created, and only packet redirection is left to configure. For the last part of the installation in the proxy server, we need to get the IP address that the VPN adapter has assigned to the final server. This address can be obtained by using:
sudo ip a
And then it will be located in the inetsection of the corresponding adapter, that will have a name like ‘tun0‘. You should take note of it, as it will be required in further steps.
3: Proxy server
Once we have the VPN tunnel already set up, the last step is to create the forwarding rules that will route packets from the proxy to the final server. To do it, we will change the iptables‘ configuration.
First, export your current configuration by executing the following command:
sudo iptables-save > /path/to/config.cfg
After the previous command, the current configuration will be stored in the specified path. Next up, open it with a text editor and modify the ‘*nat‘ section with the following values:
*nat
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
# Forwarding incoming port 80 on proxy to final server IP's port 8080 through it's VPN IP
-A PREROUTING -p tcp -m tcp --dport 80 -j DNAT --to-destination IP_VPN_FINAL:8080
# Change source ips from VPN IP to VPS' IP for all outbound traffic
-A POSTROUTING -s 10.8.0.0/24 -j SNAT --to-source VPS_PUBLIC_IP
The previous example contains a forwarding rule that redirects connections arriving to proxy’s port 80, to final server’s port 8080 in the TCP protocol. However, several lines can be added to allow for different ports and protocols to be forwarded, following this pattern:
When all the desired ports are configured with their respective rules, save the file and execute the following command to import it into iptables:
sudo iptables-restore < /path/to/config.cfg
You must ensure that the proxy server has the required incoming ports and the VPN port (normally 1194 – UDP) open, to allow for the users and the final server to connect to the proxy, respectively. Furthermore, the hosted server(s) must be listening for connections on the VPN IP.
Once the configuration is saved, the installation of the reverse proxy is complete, and the real IP of the final server will not be visible from external clients, as from their perspective it is the proxy who processes the requests.
Known issues
During the configuration of this proxy on my own servers, the final server could not resolve DNS queries once connected to the VPN tunnel. Changing the DNS servers in the operating system’s configuration to Google DNS solved the problem.
Este artículo fue escrito originalmente en Inglés. Sin embargo, una versión traducida automáticamente se encuentra aquí.
Nowadays, the use of dedicated GPS devices has been relegated to a second place, as almost everyone has a smartphone with a built-in GPS to calculate the needed routes. However, lots of people still have one of those devices lying around, that they can give a second life to (or at least to tinker with).
About OpenTom
Among the different GPS brands that were popular in the past, TomTom devices are very interesting to explore, as their software is based on Linux and the brand made most of it open-source. Some years ago, in 2006, a mainly German developer team released a lightweight Linux distribution for those devices, called OpenTom.
The distribution featured a basic but functional graphical interface, drivers for the majority of the components of the different devices, and many preinstalled services (such as an FTP, SSH and Telnet server) and applications (utilities, games, audio players…). It even included support for two different GPS applications: Navit and TomTom’s original software.
Nevertheless, at that time GPS devices were still being used for its main purpose, so the community did not show much interest on the project and the official website went down in 2014. Shortly after, a French developer known as Clément Gerardin collected all the available information that he could find, and created an unofficial wiki and repository, so that the development could continue.
Fixing the compilation script
The last commit for that repository was published on January 2017, which is much more recent, but since then several dependency sources have stopped working, and the system cannot be directly compiled following the indicated steps. A few weeks ago, I was looking for alternative uses for my TomTom XXL IQ Routes that I no longer use, and I found this project.
Figure 1. TomTom XXL IQ Routes running OpenTom
When I noticed that I could not directly compile the system, and that the link for a precompiled version was no longer available, I decided to try to fix the missing dependencies and errors, so that I could compile it.
After adding some missing dependencies (that were not specified in the documentation) and looking for updated links for many of them, the base system was able to compile. The extra applications that can be installed come on a separate script, that also needed some tweaks (and to remove some applications which I could not find a working link for).
Finally, I could compile the whole system and most of the applications, and the source code with all of those fixes is now available as a fork of the original repository aquí. I used a clean installation of Ubuntu 20.04 LTS to test it and it worked perfectly, following the detailed steps.
Compatibility issues
Despite the age of the project, a detailed list of all the GPS models that this distribution supports is not available. The only information that can be found is the report of some community members that have successfully tested it on their devices.
In any case, after reviewing the boot and install scripts during the task of updating them, it can be seen that several parts of the code take into account different internal hardware and software combinations, trying to support as many models as possible.
The devices that are confirmedto be supported by OpenTom (either by the developers or by the community) are:
TomTom One XL
TomTom One (v2)
TomTom Go 730
In my case, all features related with Bluetooth did not work, as my device does not feature a Bluetooth antenna.
Final remarks
This project is a really interesting way to give a new lease of life to a disused kind of devices, and also as a starting point for further development related with them.
I would like to emphasise that the full credit for the development of OpenTom must be given to its original creators, but also to the community that gathered all the available resources when the original ones were not available. My contribution to it was only to (re)gather some resources and to update them so that this software could still be used.
In case of any doubt or issue about the OpenTom distribution, feel free to contact me, but preferably contact its developers, that will have a deeper knowledge about its operation.
Este artículo fue escrito originalmente en Español. Sin embargo, una versión traducida automáticamente se encuentra aquí.
Una versión de este artículo en formato PDF lista para imprimir también está disponible aquí.
A veces resulta interesante poner a prueba diferentes conceptos teóricos y algoritmos utilizados en diferentes ramas de las matemáticas, y comprobar su grado de correspondencia y precisión respecto a la realidad.
En este caso el objetivo del estudio fue analizar un algoritmo incluido dentro del espectro de la teoría de grafos, conocido como el Cartero Chino. Este algoritmo permite, definido en base a conceptos de la rama previamente mencionada, obtener un camino cerrado de longitud mínima que visite todas las aristas de un grafo dado al menos una vez. Para grafos ponderados (como el utilizado en este caso), la longitud es definida como la suma de los pesos de cada arista que forma parte del camino.
Para ello se ha modelado la red de líneas y paradas de Metro Madrid, intentando obtener un camino que permita recorrerla en el menor tiempo posible, considerando además que el recorrido debe comenzar y terminar en el mismo punto (es decir, en la misma parada) y pasar al menos una vez por todas las paradas.
Punto de partida
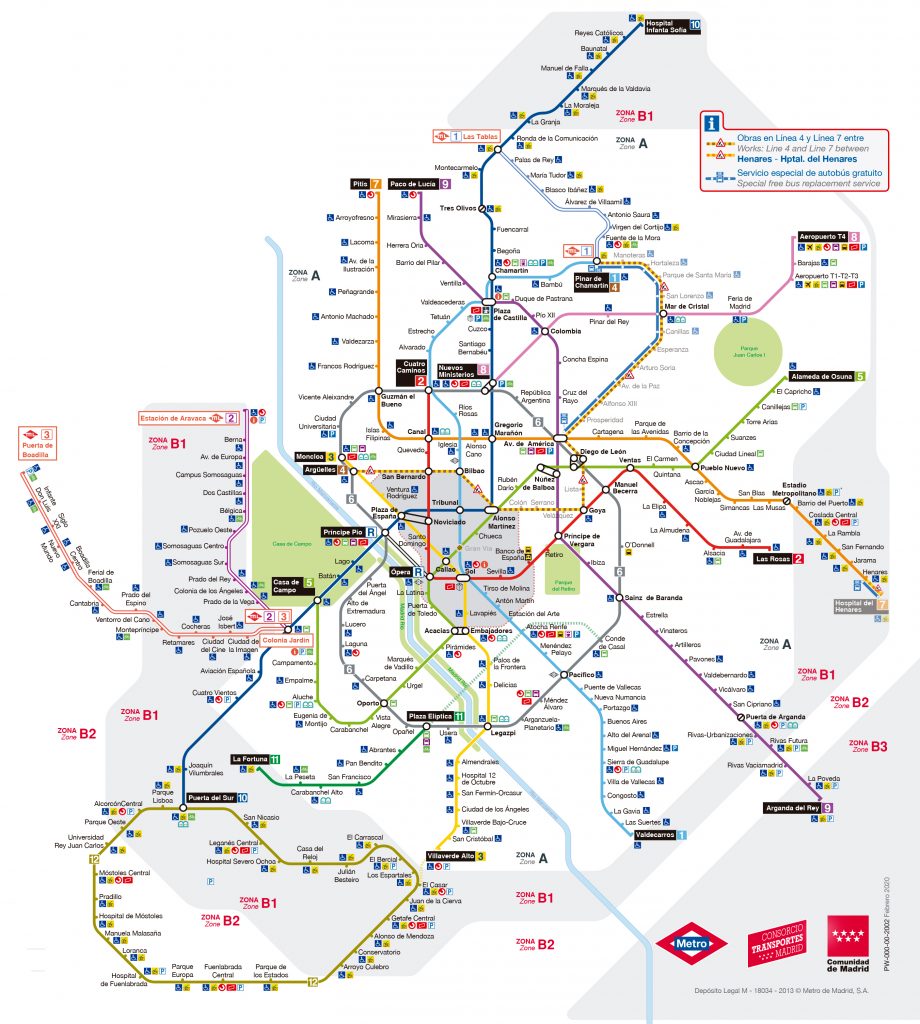
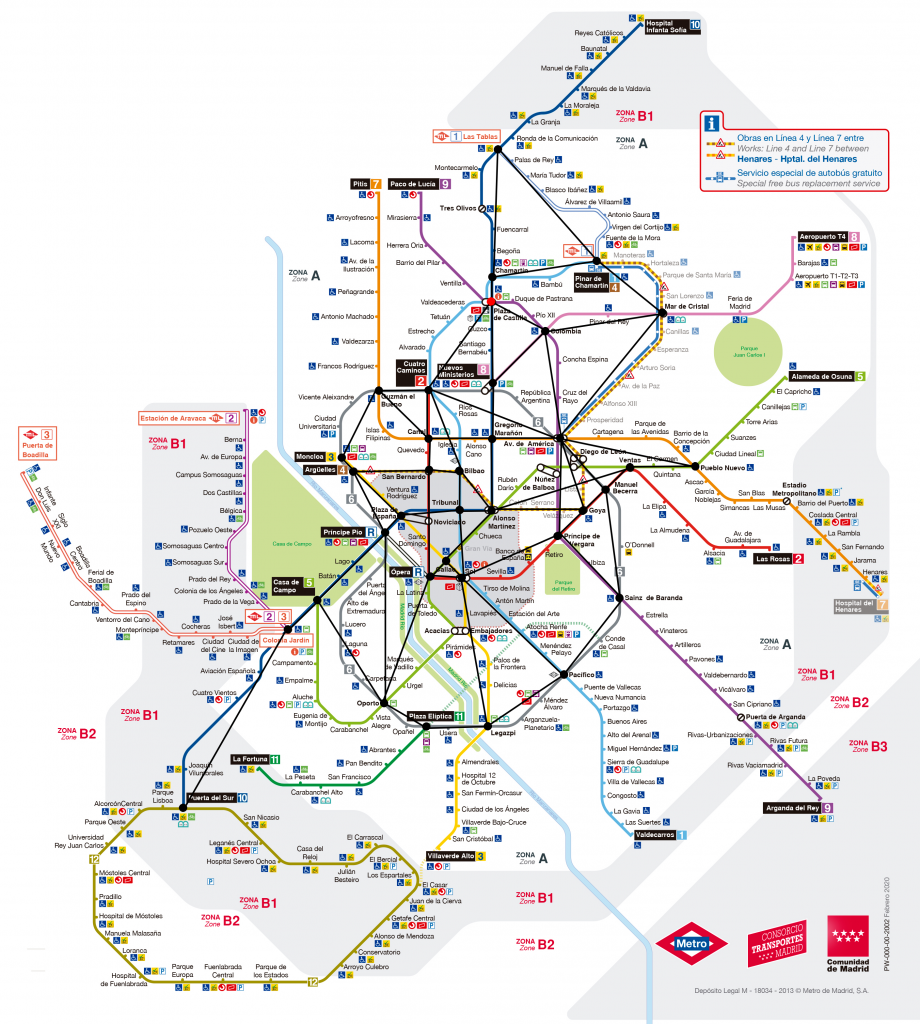
El punto de inicio sobre el que se comenzó a modelar el grafo fue el mapa más actualizado de la red de Metro Madrid al momento de realizar la prueba (actualizado a fecha de Febrero de 2020), que se muestra a continuación:
Figura 1. Mapa de Metro Madrid (actualizado: Febrero 2020)
Características del grafo
En base a las características del problema a abordar, se han considerado las siguientes variables para el grafo utilizado:
Vértices: aquellas paradas que permiten un transbordo entre varias líneas. Se han descartado aquellas que, aunque en el mapa original figuran como opción de transbordo, requieren atravesar un pasaje a pie de una longitud no despreciable.
Aristas: trayecto de una o más líneas (mayoritariamente sólo una) entre dos estaciones.
Ponderado: se define el peso de cada arista como el tiempo estimado que se tarda en recorrer el trayecto desde su vértice de origen a su vértice de destino[1].
No dirigido: como las líneas de metro en cada parada permiten dirigirse hacia ambas direcciones, se han incluido las dos en una sola arista sin dirección definida.
Finalmente cabe remarcar que el grafo no contiene ningún bucle, ya que carece de sentido ir de una parada a sí misma, y tampoco contiene diferentes aristas entre un mismo par de vértices en aquellos casos en los que dicho trayecto se puede realizar en más de una línea, ya que se asume que el trayecto va a tener la misma duración independientemente de la línea en que se realice.
Herramientas utilizadas
Para la correcta realización del análisis y con el objetivo de acelerar tanto el modelado del grafo como la ejecución del algoritmo, el siguiente software y librerías fueron utilizadas:
Adobe Photoshop CC, para trazar sobre el mapa de la red de Metro Madrid el primer boceto del grafo, remarcando las paradas y los trayectos convenientes y facilitar su posterior transformación al código.
Librería JGraphT, basada en Java, que incluye las clases necesarias que implementan el tipo de grafo deseado, y permite ejecutar el algoritmo del Cartero Chino[2].
Obtención del grafo
En primer lugar, y antes de comenzar con cualquier otra fase, se comprobó el funcionamiento de las librerías elegidas, siguiendo ejemplos con resultados ya conocidos[3].
Una vez comprobado el adecuado funcionamiento de dichas librerías se comenzó con el modelado del grafo, marcando sobre el mapa previamente mostrado las paradas de interés y sus correspondientes trayectos. Finalizada esta etapa, el mapa/grafo se encontraba en el siguiente estado:
Figura 2. Primera etapa del modelado del grafo
Como se puede observar, sobre la red original de paradas y líneas se encuentran marcadas con puntos negros aquellas paradas que incluyen transbordos entre varias líneas, y éstas se encuentran unidas entre sí en base a los trayectos que las unen pero dispuestas en línea recta, para facilitar la representación visual posterior del grafo final.
Se eliminaron del grafo los trayectos que no incluyen ningún transbordo y que representan el final de cada línea, ya que se conoce que la única manera de recorrerlos sería linealmente, en un trayecto de ida seguido del mismo trayecto de vuelta, sin ningún transbordo durante ese recorrido. De este modo, posteriormente se detalla que, una vez el camino alcanza uno de estos recorridos, se deben recorrer de la manera especificada, sin ser necesario que esto sea representado en el modelo.
Seguidamente, eliminando ya el fondo del mapa original, se añadieron etiquetas a los vértices (paradas) del grafo, representados por el nombre de cada una de las paradas, y también se rellenaron los pesos que corresponden a cada una de las aristas (trayectos), expresados en minutos de trayecto. De esta forma se asegura el parecido a la realidad, ya que los trayectos en Metro Ligero son más costosos debido a los vagones en los que se realizan, que viajan a una menor velocidad.
No se ha considerado en el cálculo del peso de las aristas el tiempo de espera a la llegada del tren ni el de transbordo (salir de un vagón de una línea y entrar a otro), ya que es un valor muy variable y que añadiría imprecisión al resultado final. Posteriormente, en la puesta en práctica de la ruta, se podría obtener una media del tiempo de espera debido a los factores mencionados.
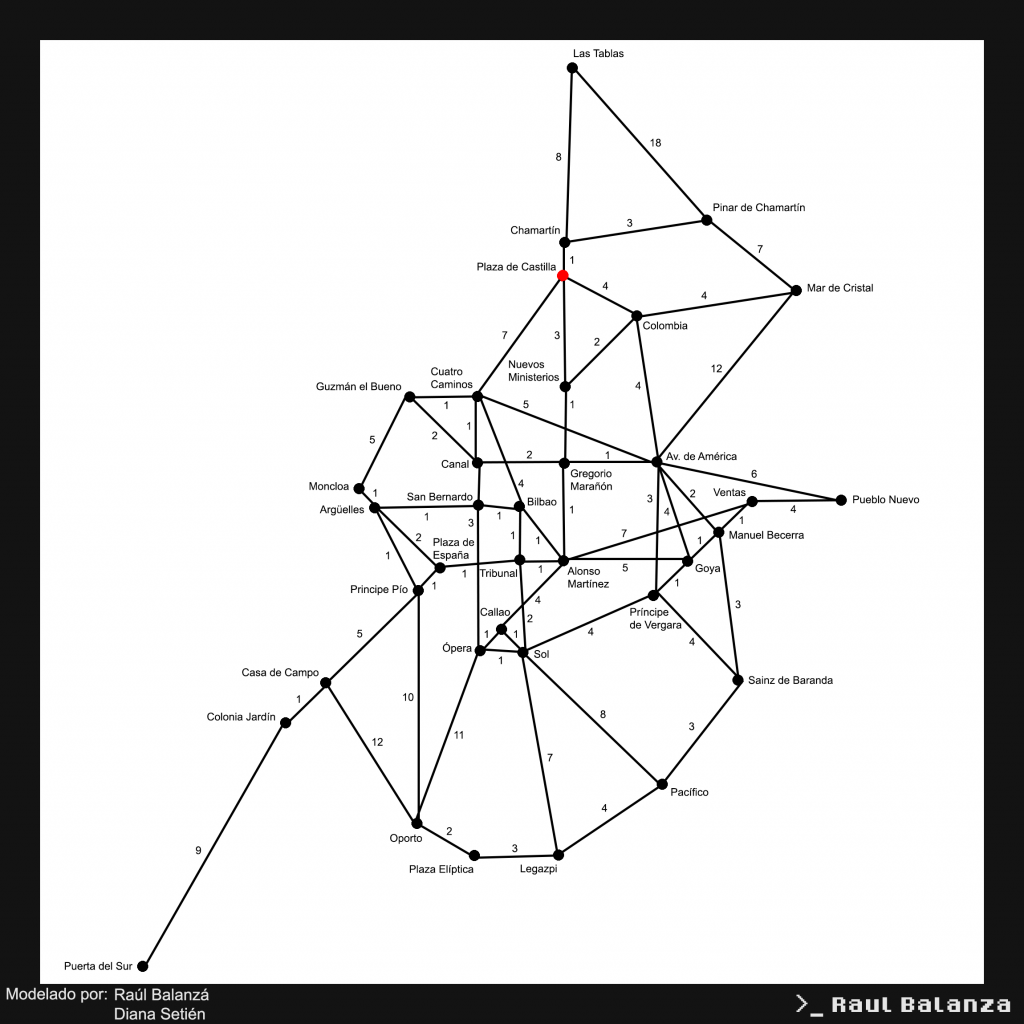
Considerados todos los puntos anteriores, y realizadas las modificaciones especificadas, el grafo de 36 vertices y 64 aristas finalmente queda como se muestra a continuación:
Figura 3. Grafo final de transbordos de la red de Metro Madrid
Ejecución del algoritmo
Una vez obtenido el grafo, se procedió a su adaptación a la sintaxis y la estructura impuesta por la librería JGraphT, elegida para la representación del grafo en código y la ejecución del algoritmo.
En este enlace se encuentra el código utilizado para la generación del grafo y para el cálculo del camino obtenido por el algoritmo del Cartero Chino. La lista de paradas y de trayectos considerada también está disponible.
La ejecución de el algoritmo siguiendo la implementación de la librería elegida tiene un coste temporal asintótico de O(N3), siendo N el número de vértices. Sin embargo, dado el tamaño del grafo obtenido, el tiempo de ejecución fue mínimo en este caso.
Al finalizar, se obtiene como resultado del cálculo la sucesión de transbordos a realizar, a partir de la cual se puede deducir el camino a seguir. También se puede estimar el coste total en tiempo de la realización del recorrido, definido como la suma de los pesos de todas las aristas que conforman el camino, y teniendo en cuenta las limitaciones previamente especificadas, es decir, sin tener en cuenta el tiempo de transbordo ni de espera al tren, y a falta de añadir el tiempo necesario para recorrer aquellos trayectos de ida y vuelta que representan los finales de línea y algunas líneas de Metro Ligero.
Trayectos lineales
Antes de detallar los resultados finales obtenidos tras la ejecución del algoritmo, conviene estimar el tiempo de duración de aquellos trayectos que no han sido considerados en el modelo original, para poder añadirlos a dicho análisis y obtener así una estimacion realista del tiempo requerido para recorrer toda la red de Metro Madrid.
Todos los trayectos se muestran con su tiempo duplicado, ya que se tiene en cuenta tanto el trayecto de ida como el de vuelta. Dichos trayectos son los que se listan a continuación, junto a su duración:
Colonia Jardín <-> Puerta de Boadilla: 36 * 2 = 72 minutos.
Colonia Jardín <-> Estación de Aravaca: 21 * 2 = 42 minutos.
Plaza Elíptica <-> La Fortuna: 10 * 2 = 20 minutos.
Legazpi <-> Villaverde Alto: 13 * 2 = 26 minutos.
Pacífico <-> Valdecarros: 26 * 2 = 52 minutos.
Sainz de Baranda <-> Arganda del Rey: 32 * 2 = 64 minutos.
Ventas <-> Las Rosas: 9 * 2 = 18 minutos.
Pueblo Nuevo <-> Hospital del Henares: 22 * 2 = 44 minutos.
Pueblo Nuevo <-> Alameda de Osuna: 11 * 2 = 22 minutos.
Mar de Cristal <-> Aeropuerto T4: 11 * 2 = 22 minutos.
Plaza de Castilla <-> Paco de Lucía: 10 * 2 = 20 minutos.
Guzmán el Bueno <-> Pitis: 10 * 2 = 20 minutos.
Puerta del Sur <-> Puerta del Sur (Línea 12 – circular): 32 minutos.
Todos los trayectos mencionados suman un total de 488 minutos adicionales (≈8.14 horas), un tiempo significativo a considerar.
Una vez más, cabe remarcar que sería necesario obtener una estimación media del tiempo de espera y de transbordo, que debería ser multiplicada por el número de transbordos realizados y sumada a los resultados que se exponen en la sección siguiente.
Resultados del análisis
Una vez consideradas todas las variables en el análisis, a continuación se presentan los datos obtenidos: el algoritmo del Cartero Chino obtuvo un camino eficiente para recorrer el núcleo de la red de Metro Madrid (la zona que abarca el grafo) en un tiempo aproximado de 273 minutos. Esta duración de trayecto se ve superada en gran magnitud por aquellas zonas que no pueden ser optimizadas, al solo disponer de una posibilidad de recorrido, añadiendo este factor un total de 488 minutos al recorrido previamente mencionado.
El total de tiempo en el que se podría recorrer, por tanto, la red de Metro Madrid, es de 761 minutos (unas 12.7 horas) + el tiempo necesario para esperar a los trenes y realizar transbordos. Obtenidos estos resultados, cabe destacar que sería técnicamente posible realizar este recorrido en un sólo dia de funcionamiento de la red, que está activa durante 20 horas al día, asumiendo que el tiempo de espera no supera en la mayoría de casos al de trayecto.
El camino requerido para poder obtener estos resultados se describe a continuación, a modo de lista de estaciones en las que realizar transbordo, situando el comienzo (y el final) de la ruta en la estación de Plaza de Castilla, y siempre considerando que se realizan las rutas lineales descritas previamente al llegar a su parada de comienzo:
[Plaza de Castilla, Cuatro Caminos, Guzman el Bueno, Moncloa, Arguelles, Principe Pio, Oporto, Plaza Eliptica, Legazpi, Pacifico, Sainz de Baranda, Manuel Becerra, Ventas, Pueblo Nuevo, Av. de America, Mar de Cristal, Colombia, Nuevos Ministerios, Gregorio Maranon, Alonso Martinez, Ventas, Manuel Becerra, Sainz de Baranda, Principe de Vergara, Sol, Pacifico, Legazpi, Sol, Opera, Oporto, Casa de Campo, Colonia Jardin, Puerta del Sur, Colonia Jardin, Casa de Campo, Principe Pio, Plaza de Espana, Tribunal, Sol, Callao, Sol, Tribunal, Alonso Martinez, Goya, Principe de Vergara, Av. de America, Manuel Becerra, Goya, Av. de America, Gregorio Maranon, Canal, San Bernardo, Bilbao, Alonso Martinez, Callao, Opera, San Bernardo, Arguelles, Plaza de Espana, Tribunal, Bilbao, Cuatro Caminos, Canal, Guzman el Bueno, Cuatro Caminos, Av. de America, Colombia, Nuevos Ministerios, Plaza de Castilla, Colombia, Mar de Cristal, Pinar de Chamartin, Chamartin, Pinar de Chamartin, Las Tablas, Chamartin, Plaza de Castilla]
Después de añadir al camino anterior las rutas lineales y de detallar los trayectos a seguir para llegar a los diferentes vértices del mismo, se obtiene la ruta completa a través de la red de Metro Madrid, que está disponible en este documento.
Conclusiones
Como punto final a este análisis, puede afirmarse que queda demostrada la (poca) viabilidad de realizar el recorrido de toda la red de Metro Madrid en el tiempo limitado de un día, incluso intentando maximizar su eficiencia.
Resulta llamativo observar la diferencia entre la duración del recorrido optimizado del núcleo de la red, que es prácticamente duplicada por la de una zona no optimizable, como es la periferia de la misma. Esto deja en evidencia la utilidad del algoritmo utilizado, y la importancia de hacer uso de herramientas como esta al realizar estimaciones de gran magnitud, lo cual era un objetivo principal del análisis expuesto en este artículo.
Sin embargo, independientemente de la utilidad práctica del análisis que aquí se expone, diferentes datos y mediciones pueden ser extraídos para otros propósitos. A modo de ejemplo, el grafo modelado de la red de Metro Madrid, con la adición de los trayectos lineales no incluidos, podría utilizarse junto a otros algoritmos como el algoritmo de Dijkstra, que permitiría obtener el camino más corto para realizar el trayecto desde una estación a otra, una aplicación muy útil y comunmente utilizada por los usuarios de transporte público.
Autores
Raúl Balanzá: modelado del grafo, programación y redacción
Diana Setién: modelado del grafo
Referencias
[1]Citymapper: estimaciones de tiempo para todos los trayectos
[2]JGraphT: librería programada en Java para uso de grafos
[3]The Postman Problems, Universidad de La Laguna: ejemplos conocidos del algoritmo del Cartero Chino